
机器学习与深度学习
什么是机器学习
传统编程:人提供数据,并且提供规则(代码),让程序执行 →
f(input) = output机器学习:把传统编程翻转过来,人给数据和答案,机器自己找规则 → 从数据中学习规则,也就是找到一个终极函数
f,这个函数可能极其复杂,有着极高的参数量。
机器学习不是靠人来写if else,而是让机器通过数据去拟合一个极其复杂的函数。
什么是深度学习
机器学习是人工智能的一个子集,而深度学习是机器学习的一个子集。
深度学习本质上就是机器学习,只不过它用了一类特殊的模型——深度神经网络。
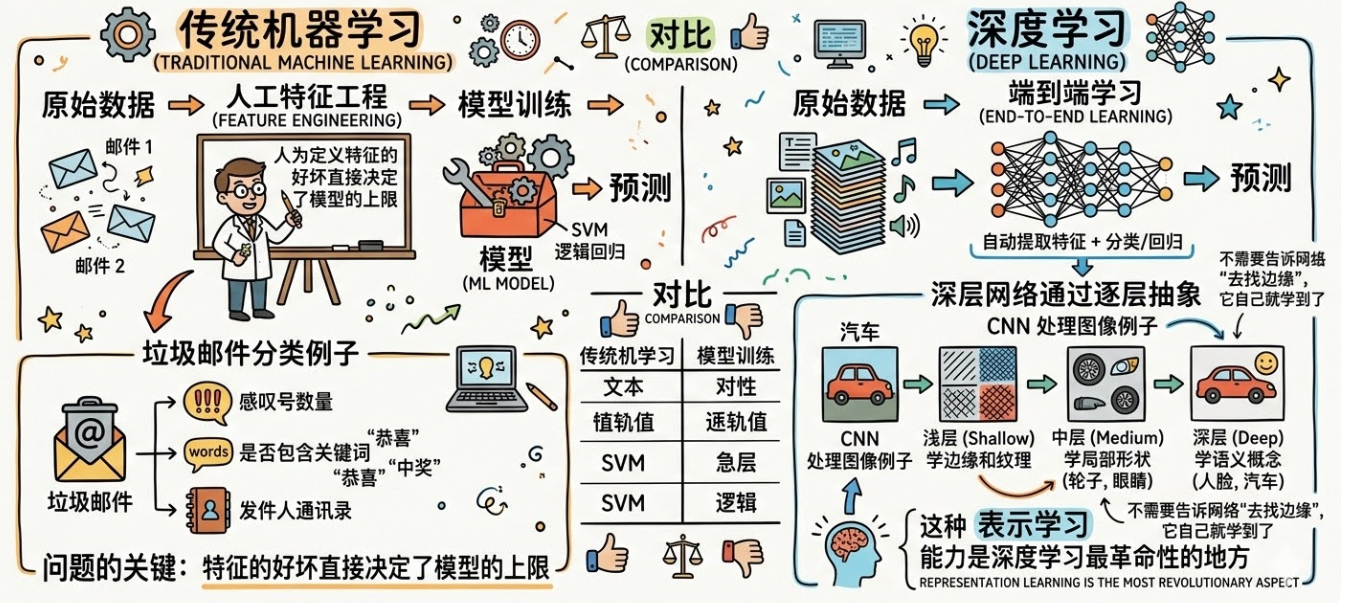
传统机器学习和深度学习的区别
原始数据-->人工设计工程(特征工程)-->模型训练-->预测
举个例子:你要做垃圾邮件分类,你需要人为定义"邮件中感叹号数量""是否包含特定关键词""发件人是否在通讯录中"等特征,然后喂给 SVM 或逻辑回归。
问题的关键就在这一步:特征的好坏直接决定了模型的上限。
而深度学习则选了另外一条路线:
原始数据 → 端到端学习(自动提取特征 + 分类/回归)→ 预测
深度网络通过逐层抽象,自动从原始数据中学到层次化的特征表示。以 CNN 处理图像为例——浅层学边缘和纹理,中层学局部形状(眼睛、轮子),深层学语义概念(人脸、汽车)。你不需要告诉网络"去找边缘",它自己就学到了。这种表示学习能力是深度学习最革命性的地方。
传统机器学习是"你告诉模型看什么",深度学习是"模型自己学会看什么"
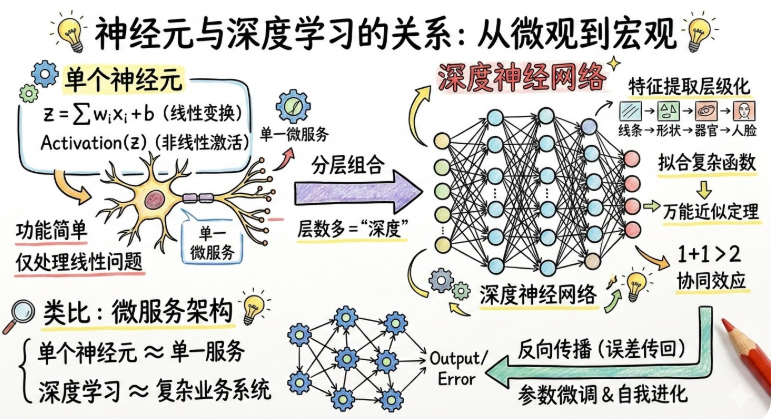
经元就是"线性变换 + 非线性激活",本身很弱。但把很多神经元分层组合起来,就能拟合极其复杂的函数——这就是深度学习中"深度"的含义。
至于为什么必须要有非线性激活这一步,是因为无数的线性叠加最终也是线性,必须通过非线性激活后,才能更好的表达模拟各种复杂的函数。
可以类比微服务架构:单个服务功能简单,但组合在一起能处理复杂业务。
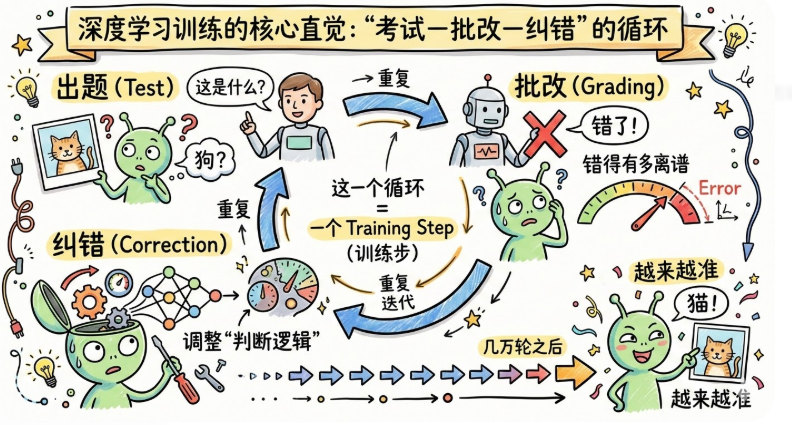
深度学习的训练过程
深度学习训练本质上就是"考试—批改—纠错"的循环。
想象你在教一个完全不懂中文的外国人学中文。你的方法是:
出题:给他看一张猫的图片,问"这是什么?"
他回答:他瞎猜,说"狗"
批改:你告诉他错了,而且告诉他错得有多离谱
纠错:他根据你的反馈调整自己的"判断逻辑"
重复:再出题,再批改,再纠错……几万轮之后,他越来越准
深度学习训练,就是这个过程的数学化版本。每一轮循环,叫做一个训练步。
这对应了深度学习训练的四个核心步骤:
传播-->学生答题
计算损失-->批改试卷,打分
反向传播-->找到每个参数的改进方向
参数更新-->纠正错误
深度学习训练 = 不断重复"预测 → 算差距 → 找原因 → 改参数"这个循环,直到模型的预测足够好。
Transformer之前的世界
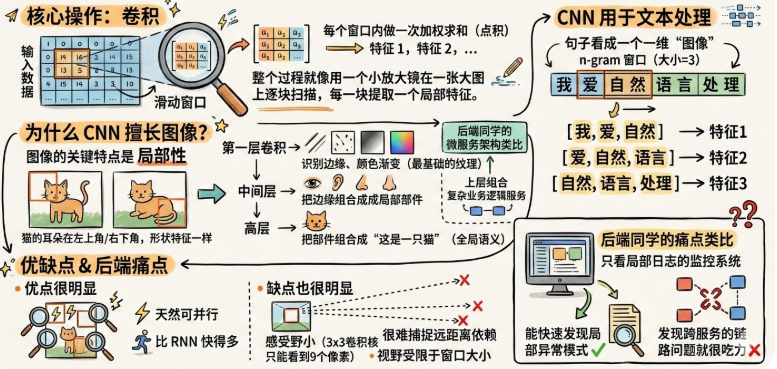
CNN,卷积神经网络
CNN 的本质就是一个固定大小的滑动窗口在数据上扫描。
优点:每个窗口的计算互不依赖,天然可并行——就像你可以开多个线程同时扫描图像的不同区域。比 RNN 快得多。
缺点:视野受限于窗口大小。一个3×3的卷积核只能看到局部的9个像素。虽然可以通过堆叠多层来间接扩大感受野,但这种间接的长距离依赖效率很低。对于文本来说,如果一个关键的上下文线索在很远的地方,CNN很难捕捉到。
RNN,循环神经网络
RNN 就像一个单线程的 for 循环,逐个处理序列中的元素:
每处理一个词,它会把当前的"理解"(hidden state)传给下一步。就像你在读一篇文章,脑子里维护着一个"到目前为止我读到了什么"的状态。
优点:它天然理解顺序——"我吃了饭"和"饭吃了我"会产生不同的结果,因为处理顺序不同。
缺点:长距离健忘症,这就好比一个没有持久化的内存变量,每次循环都会被部分覆盖。当句子很长时,早期的信息会被逐步"冲淡"。
想象一个场景:你在处理一个超长的消息队列,每条消息处理时只能看到上一条的摘要,而不能回头翻看原始消息。处理到第100条的时候,第1条的信息基本丢光了。
RNN的改进:可以给RNN 加门控机制,类似于给变量加了一个选择性写入的策略:哪些信息该保留、哪些该丢弃、哪些该更新,通过学习来决定。但本质上还是单线程顺序处理,长文本依然吃力,而且完全没法并行。
Transformer核心架构
自注意力机制
初始:girl eats apple on the table,女孩在桌上吃苹果。
注意力机制会让每个单词关注句子中的所有其他单词,询问哪些是和自己相关的。
拉取其他单词的信息来增强当前的单词(聚合上下文)
最终每个单词都得到了增强,内在包含了自己最关注的上下文信息。
具体实现
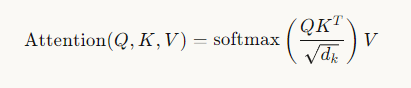
如图所示:输入是一组向量,每个向量对应了一个词,输出是另外一组向量,他不仅对应了一个词,还包含了这个词关注的上下文信息。
也就是说输出向量b1~b4是考虑了整个序列a1~a4之后才生成出来的。
自注意力的目的是考虑整个序列,但是又不想把整个序列的所有信息都包含在一个向量里面。它设计了一种机制,可以根据向量找到整个序列里面哪些是最重要的。
两个向量的关联程度可以使用点积来计算。
为什么点积可以用来表示关联程度?
拿到向量关联性结果后,再去再去提取每个向量里面他关注的信息。
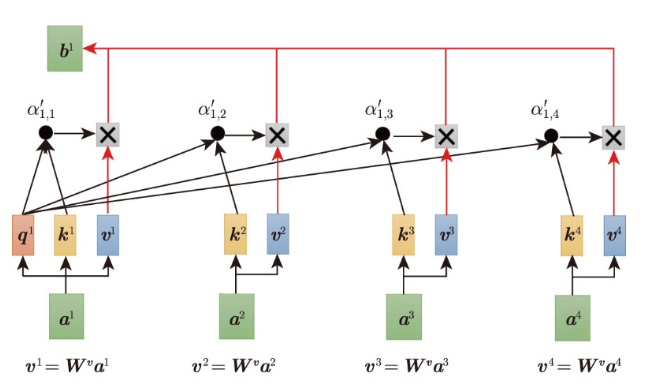
Self-Attention 的本质可以理解为一个软性信息检索过程:
Query:"我(位置1)需要什么信息?"
Key:"我(每个位置)提供什么类型的信息?"
Value:"我(每个位置)实际包含的信息内容是什么?"
点积 + Softmax:计算 query 和每个 key 的匹配程度,决定从每个位置提取多少信息
加权求和:按匹配程度,把各位置的 value 混合起来,形成当前位置的新表示
数据融合在一起后,就形成了一个更丰富的、已经融合了上下文信息的新表示。
举个例子:在调一杯鸡尾酒,45% 橙汁、26% 柠檬汁、14% 苏打水、14% 糖浆。调好之后,你不需要再把它们分离出来——这杯酒的味道本身就体现了各成分的配比。
核心思想:Attention is All You Need
Transformer的革新:既不按顺序读,也不再用滑动窗口,而是选择让每个词直接去查询它和所有其他词的关系。
为什么这会比RNN和CNN强:一步到位的全局视野。 不管两个词距离多远,在 Attention 计算里都只需要计算一次点积。没有 RNN 的"信息需要逐步传递"的瓶颈,也没有 CNN 的"视野受窗口限制"的问题。
transformer的全流程,从训练到推理
编码器部分(结构图的左半边)
编码器的核心任务:总揽全局,深刻理解输入,并将其转化为富含上下文信息的特征表示。
分词,Tokenization
第一步,分词,以“机器学习”为例,机器学习会被分词器切分为多个token。
假如会被切分为
["机", "器", "学", "习"]
每个token都会被映射为一个整数ID。(查词表)
假设的 token ID
[2001, 3045, 1567, 889]
嵌入,Input Embedding
每个 token ID 通过一个 Embedding 矩阵(大小为 V × d_model,V=词表大小,d_model=512)查表得到一个稠密向量。
"机" → [0.12, -0.34, 0.56, ..., 0.78] ← 512维向量
"器" → [0.23, 0.45, -0.67, ..., 0.11]
"学" → [-0.15, 0.89, 0.33, ..., -0.42]
"习" → [0.67, -0.21, 0.44, ..., 0.55]这个时候会得到一个矩阵X,4个token,512个维度。此时每个向量只包含语义信息,还不知道自己在句子中的位置。
注意:这些向量是随机初始化的,训练过程中会不断更新,让语义相近的词在向量空间中靠近。【但是模型一旦训练完成,这个嵌入矩阵就固化下来了,此时固定的tokenid拿到的是完全一致的嵌入向量,所以说嵌入层本质上是一个学习出来的词典】
位置编码
上一步拿到的向量只有语义信息,没有位置信息,这个步骤会给每个向量注入位置信息。
它是将位置向量(PE)和词嵌入向量(X)直接相加。由于词嵌入通常是在高维空间中,这种相加操作可以在不破坏词义的前提下,把位置信息融入其中。【可以理解为原始的语义向量中,现在加入了位置信息】
对于我们的4个位置(0,1,2,3),生成4个512维的位置向量,然后与嵌入逐元素相加,加完之后,每个向量同时携带了"我是什么词"和"我在第几个位置"两种信息。
多头自注意力
Transformer 最核心的模块。目标是让每个 token "看到"整个序列的其他 token,并决定该关注谁。
生成Q、K、V
Q(查询):「我在找什么信息?」
K(键):「我能提供什么信息?」
V(值):「我实际携带的信息内容」
分成多头
各自计算注意力分数
加权求和(每个向量融入他最关注的上下文信息)
拼接多头注意力【不同的注意力,包含了关注的不同层次】
残差连接和层归一化
残差连接:将原始输入直接加到注意力输出上,缓解深层网络的梯度消失问题。
简单理解:子层只需要学习"在原始信息基础上还需要补充什么",而不是从零开始重新构建全部信息。这个学习任务要简单得多。
举个例子:团队在开会,但是开会开着跑偏了,这一波开会中你收集到的都是无用的垃圾信息,对于结果没有帮助,残差连接的作用就是强制把你最初的想法加回来。它保证了信息的保底传递——就算刚才那场会议开得很烂,什么都没讨论出来,起码你还保留着开会前的原始信息,不至于全盘崩盘。这种不忘初心的机制,让 Transformer 可以被堆叠得非常深(比如几百层)而不会坏掉。
层归一化:在残差相加之后,对结果做归一化处理——把每个样本的特征向量调整为均值接近0、方差接近1
这一步的意义是:经过自注意力或前馈网络计算后,数值的分布可能变得很不稳定——有的特别大,有的特别小。层归一化把数值拉回到一个稳定的范围,这样做有两个好处:训练更稳定,收敛也更快。
举个例子:经过激烈的讨论(Attention)和深度思考(FFN)后,团队里有些人的情绪可能会非常激动(数值爆炸),声音大到掩盖了所有人;而有些人的声音又变得极小。 层归一化就像是一个极其专业的会议主持人。每次讨论告一段落,主持人就会强行把所有人的音量调节到一个标准的、舒适的范围内。不管你刚才多激动,现在大家都用均匀的音量交流。这样保证了整个团队(模型)的计算始终在一个稳定、健康的状态下进行。
全连接前馈神经网络FFN(Feed-Forward Network)
这一层的作用是对每个位置的表示做独立的非线性变换。如果说自注意力是让 token 之间交换信息("社交"),那 FFN 就是让每个 token 自己"消化吸收"刚获得的信息。
简单理解的话,这一层可以理解为知识库,里面有大量的世界知识。这些知识就存储在这一层的权重里面。
对比的看:
多头自注意力:目的是收集全局上下文信息,让每个词都融入当前的语境。
举个例子:所有人在一起开会交流,每个成员都会听取其他人的意见,看看别人掌握的信息跟自己有什么关系。
全连接前馈网络:目的是对刚刚收集到的信息进行深加工,把表面信息转化为更深层次的语义理解。
举个例子:开会后每个人不再互相交流,而是拿着刚才收集到的大量信息,结合自己大脑中的专业知识进行独立思考、加工总结,形成自己的结论。
自注意力机制决定了去哪里找信息(横向信息交互),全连接前馈网络决定了如何理解这些信息(纵向信息提取)。两者交替进行,模型就逐渐理解了原始复杂的文本信息。
按照团队开会来类比的话:
位置编码:进场前给每个人发座位牌,这样即使所有人同时说话,也能知道每句话是从哪个位置发出的
多头注意力:大家集体开会,交换意见,了解全局(横向整合)。
残差与归一化 (Add & Norm):保留个人原本观点(不忘初心),并由主持人平复大家的情绪(统一音量)。
前馈神经网络 (FFN):回到工位,结合脑子里的专业知识,独立深度思考,提炼观点(纵向挖掘)。
再次残差与归一化:保留思考前的底线,再次平复情绪。
(如此循环 N次)
解码器部分(结构图的右半边)
解码器的核心任务:基于已知信息,逐步生成输出。
简历全局上下文联系(消除歧义)、提取并提纯特征(信息编码)、为解码器提供全息地图。
输出-->输出的嵌入+位置编码
解码器是自回归的,一次生成一个token。训练时用 teacher forcing,推理时逐步生成。
要让解码器产生输出,就得给它一个代表开始的特殊符号<BOS>,这是一个特殊的词元(token)。
假设当前已经生成了 <BOS>(句子开始符),要预测第一个词。Decoder 的输入是:
["<BOS>"] → 嵌入+ 多维稠密向量
掩码多头自注意力
这个和之前讲的自注意力几乎一样,只有一个核心区别:掩码。
在生成时,位置 i 的 token 只能看到位置 ≤ i 的 token,不能偷看未来的输出。
这通过在注意力分数矩阵的上三角部分填充 -∞ 实现:
假设在训练时,Decoder 同时处理 ["<BOS>", "Machine", "Learning"]:
原始分数: 加掩码后:
BOS Mac Lea BOS Mac Lea
BOS [ 2.1 3.5 1.2 ] → [ 2.1 -∞ -∞ ]
Mac [ 1.8 4.2 2.7 ] → [ 1.8 4.2 -∞ ]
Lea [ 0.9 3.1 3.8 ] → [ 0.9 3.1 3.8 ]softmax 之后 -∞ 变成 0,所以:
<BOS>只能看到自己"Machine" 能看到
<BOS>和自己"Learning" 能看到前面所有
在 Transformer 的解码器(Decoder)中,Softmax 的核心作用是将这些原始的、范围不一的分数转化为一组概率分布(权重),其总和为 1。
简单来说,它决定了在生成当前单词时,应该“投入多少百分比的精力”在之前的每一个单词上。
关键的特点:在数学上,e的负无穷趋近于 0。这就是掩码生效的时刻,那些被填充了负无穷的位置,经过这一步后,权重直接变成了 0。
用每个点的指数值除以总和。这样处理后,这一行里所有非 负无穷的位置都会变成 0 到 1 之间的数字,且相加等于 1,负无穷的位置全都变成了0.
通过掩码后的自注意力的最终效果:
一般的自注意力:
掩码自注意力
残差连接和层归一化
和之前的一样
交叉注意力
这个是连接编码器和解码器的桥梁。
其实也是注意力机制,关键的区别在于Q、K、V的来源不同。
Q来自解码器的上一层输出
但是K、V来自编码器的最终输出
举个例子:
Q = decoder_output × W_Q ← "我要翻译什么?"
K = encoder_output × W_K ← "源文有哪些信息?"
V = encoder_output × W_V ← "源文的具体内容"比如 Decoder 在生成第一个词时,Q 来自 <BOS>,它会和 encoder 输出的"机""器""学""习"的 K 做点积:
机 器 学 习
<BOS> [ 0.15 0.40 0.25 0.20 ]残差连接和层归一化+全连接浅口网络+残差连接和层归一化
和编码器相同的结构。
堆叠
解码器同样可以堆叠多层
线性映射
将 Decoder 最后一层的输出映射到词表大小的向量:
假设英文词表 V=30000,得到一个 30000 维的向量,每个位置对应一个候选词的"原始分数"。
Sortmax->输出概率
结合每个词的概率和策略,选择最终的token。
P = softmax(logits)
P("Machine") = 0.82 ← 最高
P("The") = 0.03
P("Deep") = 0.02
...选出 "Machine" 后,将它加入 Decoder 输入,继续预测下一个词 "Learning",直到生成 <EOS>(结束符)。
类比刚才的开会比喻
相当于在最终,每个人把自己经过多轮讨论和深思后的结论写在纸上交给裁判(线性投影+Softmax),裁判根据所有人的最终意见做出决策。【解码器的最后一步】
解码器的运作过程
GPT
当代大模型,比如ChatGPT,真正在做的事情只有一件,就是文字接龙。
简单理解的话:ChatGPT本身就是一个函数,输入一些东西,然后输出另一些东西。
ChatGPT会给每一个可能的输出符号一个概率,得到一个概率的分布,接下来,从这个概率分布中做采样,采样出来一个字,然后把这个字拼到原始输入上面,重复这个过程,一直遇到表示停止的符号位置。
举例:
什么是机器学习?
什么是机器学习?机
什么是机器学习?机器
什么是机器学习?机器学
。。。。。。。
chatgpt如何支持连续的对话?其实就是把从第一句开始的所有聊天记录,拼接你最新的提问,然后又给了LLM。
大模型本身是不能通过对话来更新他自己的世界知识的。他的世界知识都固化在训练时候产生的权重参数里面。
对比一下Transformer
从 Encoder-Decoder 到 Decoder-Only
原始 Transformer: Encoder 处理源语言 → 生成隐藏表示 → Decoder 通过 Cross-Attention 关注 Encoder 输出 → 生成目标语言。两个独立的模块通过 Cross-Attention 桥接。
当代 LLM: 只保留 Decoder 部分,去掉了 Encoder 和 Cross-Attention 层。输入和输出共用同一个序列空间,模型只做一件事——给定前面的所有 token,预测下一个 token。
几个问题
为什么大模型能理解我的问题?大模型这个黑盒到底在做什么?
经过海量文本训练后,模型的参数(可能几千亿个浮点数)编码了一种"语言世界模型",以一种数学结构化的方式,获得了对语言和部分世界规律的表示。
回答用户的过程,就是把用户的文字,变成一串高维向量,再让这些向量彼此提取融合对方的信息,不断加工,最后预测接下来最合适的词的过程,大模型变成了一个概率预测机器,给输入,会输出词表中所有词出现的概率,然后根据策略和概率,选择一个词进行输出。
和LLM聊天时候,LLM的回答为什么是一个一个蹦出来而不是一次性全量返回的?
解码器每运作一次,只产生一个token,然后通过自回归,来生成完整的回答。
每个生成的token,又要重新走一次完整的decoder流程。在生成第 t 个 token 时,需要知道前 t-1 个 token 是什么(掩码自注意力的因果性决定了这一点)。
自回归:用过去预测未来,然后把预测的结果又当作"过去"的一部分,继续预测下一个未来
为什么输出token比输入token贵?
假设输入了1000个token,模型可以一次性并行处理所有的输入token,因为输入已经全部都知道了,虽然掩码自注意力限制了每个位置只能看前面的 token,但这些计算相互之间没有数据依赖,所以GPU 可以同时计算所有位置的注意力。
1000个token的注意力计算可能只需要几次矩阵乘法的时间。
但是输出就完全不同了,生成每一个 token 都必须串行等待前一个 token 生成完毕。生成 100 个 output token = 100 次串行的前向传播。每次前向传播都要过完所有层,每次都在用 GPU,但每次只产出一个 token。GPU 的并行能力在这里被严重浪费了。
从硬件利用率和时间成本来看,生成 1 个 output token 的成本 ≈ 处理几十甚至上百个 input token 的成本。这就是为什么 API 定价通常 output 是 input 的 3~5 倍。
大模型API里面的cache,它到底缓存的是什么?
其实缓存的就是注意力计算时候的K和V(所以也叫做KV cache)。
参考资料
《深度学习详解》
《从零构建大模型》
《图解大模型》
